The swim team that I help out with is purchasing a timing system. The timing system’s data needs to interface with the existing datamart, which is stored in a SQL Server database. The database serves a variety of functions – from season registration, meet registration, team records, etc…
The system that the board chose is the industry leader with its own proprietary data storage mechanism. Their system does not allow any kind of RPC from a RDBMS system. The only way to get into and out of the system is via text files. These text files are structured using USA Swimming’s Standard Data Interchange Format – found here with a simplified version found here. I cracked open the RFC and was amazed – they are not using XML! Rather, it is a flat file format with each row of data conforming to certain field lengths. It is like going back to FORTRAN programming – without the sexiness of the green screen. Here is an example of a row of data:
D01 Whitaker, Taylor 122691TAY*WH 1226199118FF 1003 UNOV 1:25.00Y
And here is how the RFC tells you how to parse the payload:
Start /
Length Mandatory Type Description
1/2 M1* CONST "D0"
3/1 M2* CODE ORG Code 001, table checked
4/8 future use
12/28 M1 NAME swimmer name
40/12 M2 ALPHA USS#
52/1 CODE ATTACH Code 016, table checked
53/3 CODE CITIZEN Code 009, table checked
56/8 M2 DATE swimmer birth date
64/2 ALPHA swimmer age or class (such as Jr or Sr)
66/1 M1 CODE SEX Code 010, table checked
67/1 M1# CODE EVENT SEX Code 011, table checked
68/4 M1# INT event distance
72/1 M1# CODE STROKE Code 012, table checked
73/4 ALPHA Event Number
77/4 M1# CODE EVENT AGE Code 025, table checked
81/8 M2 DATE date of swim
89/8 TIME seed time
97/1 * CODE COURSE Code 013, table checked
Therefore, to interface with our SQL Server database, I need a way of translating the data that is in the database into the structured format (and back again).
There are a series of files – A0, B1, etc… I was thinking of making a class that is a concrete implementation of the RFC for that row of data. I then realized that I could use the power of an Object Oriented Language to make my solution less brittle and to try out some cool polymorphic techniques.
My first step was to create an Interface that handles each chunk of data. Just because USA Swimming isn’t going to use XML, it doesn’t mean I can’t use XML language syntax – heck it is all structured data.
I started with the attribute:
public interface IAttribute
{
int AttributeId { get; set; }
int Start { get; set; }
int Length { get; set; }
bool Manditory { get; set; }
AttributeType AttributeType { get; set; }
string Description { get; set; }
string AttributeValue { get; set; }
string PaddedValue { get; }
}
The AttributeValue is a string implementation of the value of the property. The PaddedValue is the same value with the padding and left/right justification applied.
I then thought about how I wanted to implement the 15 or so different elements (called “records”, which has nothing to do with swim meet records. Someone didn’t understand the importance of domain-specific language). Since the elements are fairly stable, I went with a Strategy Pattern.
Each element is a collection of Attributes. Therefore, I created one to see if I was barking up the right tree:
public class FileDescription: Collection<IAttribute>
{
public string ElementId
{
get
{
return "A0";
}
}
public string ElementDescription
{
get
{
return "File Description Record";
}
}
public FileDescription()
{
this.Add(new Attribute { AttributeId = 1, Start = 1, Length = 2, Manditory = true, AttributeType = AttributeType.CONST, Description = "A0"});
this.Add(new Attribute { AttributeId = 2, Start = 3, Length = 1, Manditory = false, AttributeType = AttributeType.CODE, Description = "ORG Code 001, table checked" });
this.Add(new Attribute { AttributeId = 3, Start = 4, Length = 8, Manditory = false, AttributeType = AttributeType.ALPHA, Description = "SDIF version number (same format as the version number from the title page)" });
etc…
}
}
I then realized that there is no easy way to get the correct Attribute from the collection except via its index number. Holding my nose, I then created a new unit test to see if I could create a fake for this class. The first test passed. I then wanted to add a ToString() override that spits out the FileDescription’s values – as if I was writing it out to the flat file. Here is what I came up with:
public override string ToString()
{
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.Append(this[0].AttributeValue);
stringBuilder.Append(this[1].AttributeValue);
…
stringBuilder.Append(this[12].AttributeValue);
return stringBuilder.ToString();
}
I then realized that I would have to duplicate this code in every class that implements the Collection<IAttribute> I then created an abstract class to handle some of this work for me:
public abstract class Record : Collection<IAttribute>
{
public string RecordId
{
get
{
return this[0].AttributeValue.ToString();
}
set
{
this[0].AttributeValue = value;
}
}
public string OrganizationCode
{
get
{
return this[1].AttributeValue.ToString();
}
set
{
this[1].AttributeValue = value;
}
}
public const int MaxRecordLength = 160;
public override string ToString()
{
StringBuilder stringBuilder = new StringBuilder();
foreach (Attribute attribute in this)
{
stringBuilder.Append(attribute.AttributeValue);
}
return stringBuilder.ToString();
}
public string ToPaddedString()
{
int padLength = 0;
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.Append(ToString());
padLength = MaxRecordLength - stringBuilder.Length;
for (int i = 0; i < padLength; i++)
{
stringBuilder.Append(string.Empty);
}
return stringBuilder.ToString();
}
}
I then changed the concrete classes to inherit from the Record class. I finished my Fake for the unit tests like this:
file[0].AttributeValue = "A0";
file[1].AttributeValue = "1";
file[2].AttributeValue = "V3";
file[3].AttributeValue = "20";
file[5].AttributeValue = "Hy-Tek, Ltd";
file[6].AttributeValue = "6.0X";
file[7].AttributeValue = "Hy-Tek, Ltd -USS";
file[8].AttributeValue = "252-633-5177";
file[9].AttributeValue = "02172011";
I then realized that I hate working with indexers so I added properties that give a friendly name to the indexer:
public string SoftwareName
{
get
{
return this[5].AttributeValue.ToString();
}
set
{
this[5].AttributeValue = value;
}
}
I then rewrote my Fake and still got green on the unit tests.
file.RecordId = "A0";
file.OrganizationCode = "1";
file.SDIFVersionNumber = "V3";
file.FileCode = "20";
file.SoftwareName = "Hy-Tek, Ltd";
file.SoftwareVersion = "6.0X";
file.ContactName = "Hy-Tek, Ltd -USS";
file.ContactPhone = "252-633-5177";
file.FileCreation = "02172011";
Tests were still green, so I feel good.
I then wanted to tackle the actual values that will be assigned to each attribute. There are two kinds of values – the value that come from the database (three is you want to count the .NET types versus the SQL Server ones) and the one that comes from/goes into the output file. The output file is a structured string file so perhaps I can just store the Value as a string and translate it into the native types. I would need a Translation Factory that takes the native types and pushes it into the string correctly – which seems like the right thing to do.
Before creating the Translation class , I created the classes that represent the data in the SQL Server database. I chose using EF.
I then added the Translation class that takes all of the datafrom the EF classes, translates it, and sticks it into the SDIF format. An example looks like this:
public List<IndividualEvent> CreateIndividualEventRecords(int meetId)
{
List<IndividualEvent> individualEvents = new List<IndividualEvent>();
IndividualEvent individualEvent = null;
using (HurricaneEntities context = new HurricaneEntities())
{
var q = from mea in context.tblMeetEventAssignments
.Include("tblMeetEvent")
.Include("tblMeetEvent.tblRaceStroke")
.Include("tblMeetEvent.tblAgeGroup")
.Include("tblMeetSwimmerCheckIn")
.Include("tblMeetSwimmerCheckIn.tblSwimmerSeason")
.Include("tblMeetSwimmerCheckIn.tblSwimmerSeason.tblSwimmer")
where mea.tblMeetSwimmerCheckIn.MeetID == meetId
select new {
FirstName = mea.tblMeetSwimmerCheckIn.tblSwimmerSeason.tblSwimmer.FirstName,
LastName = mea.tblMeetSwimmerCheckIn.tblSwimmerSeason.tblSwimmer.LastName,
DateOfBirth = mea.tblMeetSwimmerCheckIn.tblSwimmerSeason.tblSwimmer.DateOfBirth,
GenderId = mea.tblMeetSwimmerCheckIn.tblSwimmerSeason.tblSwimmer.GenderID,
RaceStrokeId = mea.tblMeetEvent.RaceStrokeID,
AgeGroupId = mea.tblMeetEvent.AgeGroupID,
AgeDesc = mea.tblMeetEvent.tblAgeGroup.AgeDesc,
RaceLengthId = mea.tblMeetEvent.tblAgeGroup.RaceLengthID};
foreach (var databaseRecord in q)
{
individualEvent = new IndividualEvent();
individualEvent.RecordId = "D0";
individualEvent.OrganizationCode = "1";
individualEvent.SwimmerName = databaseRecord.FirstName + " " + databaseRecord.LastName;
individualEvent.USSwimmingNumber = "??????";
individualEvent.SwimmerBirthDate = CreateFormattedDate(databaseRecord.DateOfBirth);
individualEvent.SwimmerAgeOrClass = "??";
individualEvent.SwimmerSex = CreateFormattedGender(databaseRecord.GenderId);
individualEvent.EventSex = CreateFormattedGender(databaseRecord.GenderId);
individualEvent.EventDistance = CreateFormattedEventDistance(databaseRecord.RaceLengthId);
individualEvent.EventStroke = CreateFormattedEventStroke(databaseRecord.RaceStrokeId);
individualEvent.EventAge = databaseRecord.AgeDesc;
individualEvent.SeedTime = "99.99";
individualEvent.EventCourseCode = "Y";
individualEvents.Add(individualEvent);
}
}
return individualEvents;
}
An example of the Individual Helper functions that does the actual translation:
public string CreateFormattedEventDistance(int raceLengthId)
{
switch (raceLengthId)
{
case 1:
return "15";
case 2:
return "25";
case 3:
return "50";
case 4:
return "100";
default:
return "0";
}
}
After hooking up all of my translations, I was ready to create an output file. All I had to do was write this
static void WriteToFile()
{
string fileName = @"C:\Users\Public\HHTest01.SD3";
MeetSetupFactory factory = new MeetSetupFactory();
Collection<string> collection = factory.CreateMeetSetUp(72);
System.IO.File.WriteAllLines(fileName, collection);
}
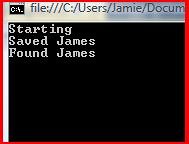
and because of polymorphism, the output came out perfectly:
A01V3 01 Tff LLC. 1.0X James Dixon 9193884228 02212011
B11 Olive Chapel Highcroft Pool 0720201007202010 Y
C11 Highcroft Hurricanes HHST 100 Highcroft Drive Cary NC27519 USA
D01 Sloan Dixon 040420Dix*Sl 040420020708MM25 2 7-8 99.99 Y
D01 Sloan Dixon 040420Dix*Sl 040420020708MM25 3 7-8 99.99 Y

")