Web Crawling Using F#
December 3, 2019 5 Comments
(This post is part of the FSharp Advent Calendar Series. Thanks Sergy Thion for organizing it)
Recently, I had the need to get articles from some United States government websites. You would think in 2019 that these sites might have apis and you would think wrong. In each case, I needed to crawl the site’s HTML and then extract the information. I started doing this with Python and its beautiful soup library but I can into the fundamental problem that getting the html was much harder than parsing the site. To illustrate, consider this website
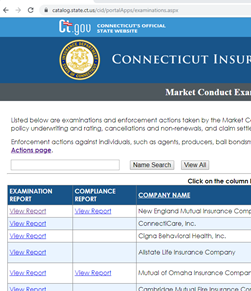
I need to go through all 8 pages of the grid and download the .pdfs that are associated with the “View Report” link. The challenge in this particular site is that they didn’t do any url parameters so there is no way to go through the grid via the uri. Looking at the page source, they are using ASP.NET and in typical enterprise-derpy manner, named their table “GridView1”
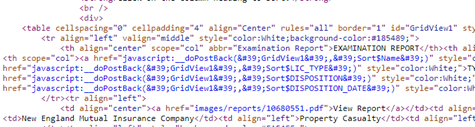
The way to get to the next page is to press on the “Next” link defined like this:
They over-achieved in the bloated View State for a simple page category though.

#Sigh
So as bad as this site is, F# made getting the data a snap. I fired up Visual Studio and created a new .NET Core F# project. I added a script file. I realized that the button-press to get to the next page was going to be a pain to program, so I decided to use the .NET framework WebBrowser class. It’s nice because it has all of the apis I needed for the traversal and I didn’t have to make the control visible.
My first function was to get the uris from the grid – easy enough using the HtmlDocument and HtmlElement classes:
let getPdfUris (document:HtmlDocument) =
let collection = document.GetElementsByTagName(“a”)
collection
|> Seq.cast
|> Seq.filter(fun e -> e.OuterText = “View Report”)
|> Seq.map(fun e -> e.GetAttribute(“href”))
Note the key word I used to filter was “View Report”, so at least the web designer stayed consistent there.
Next, I used basically the same logic to find the Next button in the DOM. Note that I am using the TryFind function so if the button is not found, a None is returned:
let getNextButton (document:HtmlDocument) =
let collection = document.GetElementsByTagName(“a”)
collection
|> Seq.cast
|> Seq.tryFind(fun e -> e.InnerText = “Next”)
So the next function was my giggle moment for this project. To “press” that button to invoke the javascript to go to the next page of the grid, I ised the InvokeMember method of the HtmlClass
let invokeNextButton (nextButton: HtmlElement) =
nextButton.InvokeMember(“Click”) |> ignore
printfn “Next Button Invoked”
Yup, that works! I was worried that I was going to have to screw around with the javascript or, worse, that beast called View State. Fortunately, that InvokeMember method worked fine. Another reason why I love the .NET framework.
So with these three functions set up, I created a method to be called each time the document is refreshed
let handlePage (browser:WebBrowser) (totalUris:List) =
let document = browser.Document
let uris = getPdfUris document
totalUris.AddRange(uris)
let nextButton = getNextButton document
match nextButton with
| Some b ->
invokeNextButton b
| None -> ()
My C#-only friends spend waaaay to much time worrying about the last page and having no button and how to code it. I used the option type – is there a Next button? Press it and do work. No Button? Do nothing.
I put in a function to save the .pdf to my local file system
let downloadPdf (uri:string) =
let client = new WebClient();
let targetFilePath = @”C:\Temp\” + Guid.NewGuid().ToString() + “.pdf”;
client.DownloadFile(uri,targetFilePath)
And now I can write this all together:
let browser = new WebBrowser()
let uris = new List()
browser.DocumentCompleted.Add(fun _ -> handlePage browser uris)
let uri = “https://www.catalog.state.ct.us/cid/portalApps/examinations.aspx”
browser.Navigate(uri)
printf “Links Done”
uris |> Seq.iter(fun uri -> downloadPdf uri)
printf “Downloads Done”
So I new up the browser, send handlePage to the DocumentCompleted event handler. Every time the Next button is pressed, the document loads and the DocumentCompleted event fires, and the .pdfs are downloaded and the next button is pressed. Until the last page, when there is no button to press.
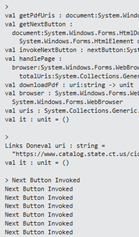
And it worked like a champ:

Gist is found here

Link to source is not available (404)
sorry, repo is now public
Pingback: F# Advent Calendar in English 2019 – Sergey Tihon's Blog
Pingback: F# Weekly #49, 2019 – .NET Core 3.1 LTS and first #FsAdvent posts – Sergey Tihon's Blog
Pingback: Web Scraping with F# – Curated SQL